TL;DR
OpenAI en Anthropic laten zelf zien dat mensen anders zoeken: lange prompts, meerdere intents, gesprekken in plaats van zoekopdrachten. De meeste GEO-tools meten dat niet. Ze testen losse prompts in een lege sessie, terwijl de aanbeveling valt in een gesprek vol persoonlijke context dat geen dashboard ziet. Wat wel werkt: heldere positionering, intern bewijs voor specifieke situaties, een herkenbare entiteit in het hele ecosysteem, en onafhankelijke bevestiging van je verhaal. Geen geheim framework. Het echte werk gebeurt buiten het dashboard om.
Het herkenbare moment
Je tikt iets in bij ChatGPT of Claude en realiseert je halverwege dat je dit twee jaar geleden nooit zo aan Google zou hebben gevraagd. "Ik heb volgende week een lastig gesprek met een klant. De opdracht is gaandeweg veel groter geworden dan we hadden afgesproken, maar het budget is hetzelfde gebleven. Ik wil eerlijk zijn maar de relatie niet beschadigen. Help me het opbouwen." Geen korte zoekopdracht. Geen lijstje met blauwe links. En zeker geen doel om een website te bezoeken die het antwoord deels zou geven.
Voor SEO-marketeers is dit moment ongemakkelijk om twee redenen. De eerste is dat het inhoudelijk klopt: we gebruiken AI inmiddels voor vragen waar Google nooit een goed antwoord op had. De tweede is dat de meeste GEO-tools die je op de markt ziet dit gegeven negeren. Ze meten zichtbaarheid in losse testprompts en presenteren dat als strategie, terwijl de echte beslissing valt in een gesprek dat je dashboard nooit zal zien.
Dit artikel kijkt naar wat recent onderzoek laat zien over hoe mensen LLM's gebruiken, wat dat betekent voor hoe merken aanbevolen worden, en waar het werk in onze ogen écht zit.
De meeste GEO-tools negeren hoe LLM's echt worden gebruikt en dat is een probleem.
Wat OpenAI en Anthropic zelf laten zien
Het interessante aan de data die we hieronder bespreken is niet alleen wát de cijfers zeggen, maar wie ze publiceerde. Het zijn OpenAI en Anthropic zelf die dit gedrag hebben onderzocht en de resultaten naar buiten hebben gebracht. De partijen die exact kunnen zien hoe mensen hun modellen gebruiken, vinden de verschuiving kennelijk groot genoeg om er publiek onderzoek aan te wijden. Voor marketeers is dat op zichzelf al een signaal.
OpenAI publiceerde in september 2025 een grote studie naar het gebruik van ChatGPT, op basis van een geanonimiseerde sample van ruim een miljoen consumentenconversaties. De drie hoofdrollen die ze onderscheiden vatten het beeld goed samen:
49% Asking — advies, uitleg, interpretatie
40% Doing — schrijven, plannen, coderen, structureren
11% Expressing — reflectie, brainstorm, persoonlijke uiting
Die "Doing"-helft past in geen enkel klassiek SEO-framework. Daar wordt geen informatie gezocht. Daar wordt iets gemaakt: een mail, een outline, een stuk code, een shortlist. Voor klassieke zoekmachines is die helft van de markt simpelweg onzichtbaar, want er is nooit een SERP gegenereerd.
Anthropic publiceerde vorige week zijn eigen analyse van een sample van een miljoen Claude-conversaties (ongeveer 639.000 unieke gebruikers). Daaruit bleek dat ongeveer 6% van alle gesprekken bestaat uit persoonlijke begeleiding: vragen als "Moet ik deze baan aannemen?", "Hoe spreek ik mijn buurman aan?", "Verhuis ik naar het buitenland?". Drie kwart van die guidance-gesprekken viel in vier domeinen: gezondheid en welzijn (27%), werk en carrière (26%), relaties (12%) en persoonlijke financiën (11%). Mensen zoeken hier geen informatie. Ze zoeken een tweede mening.

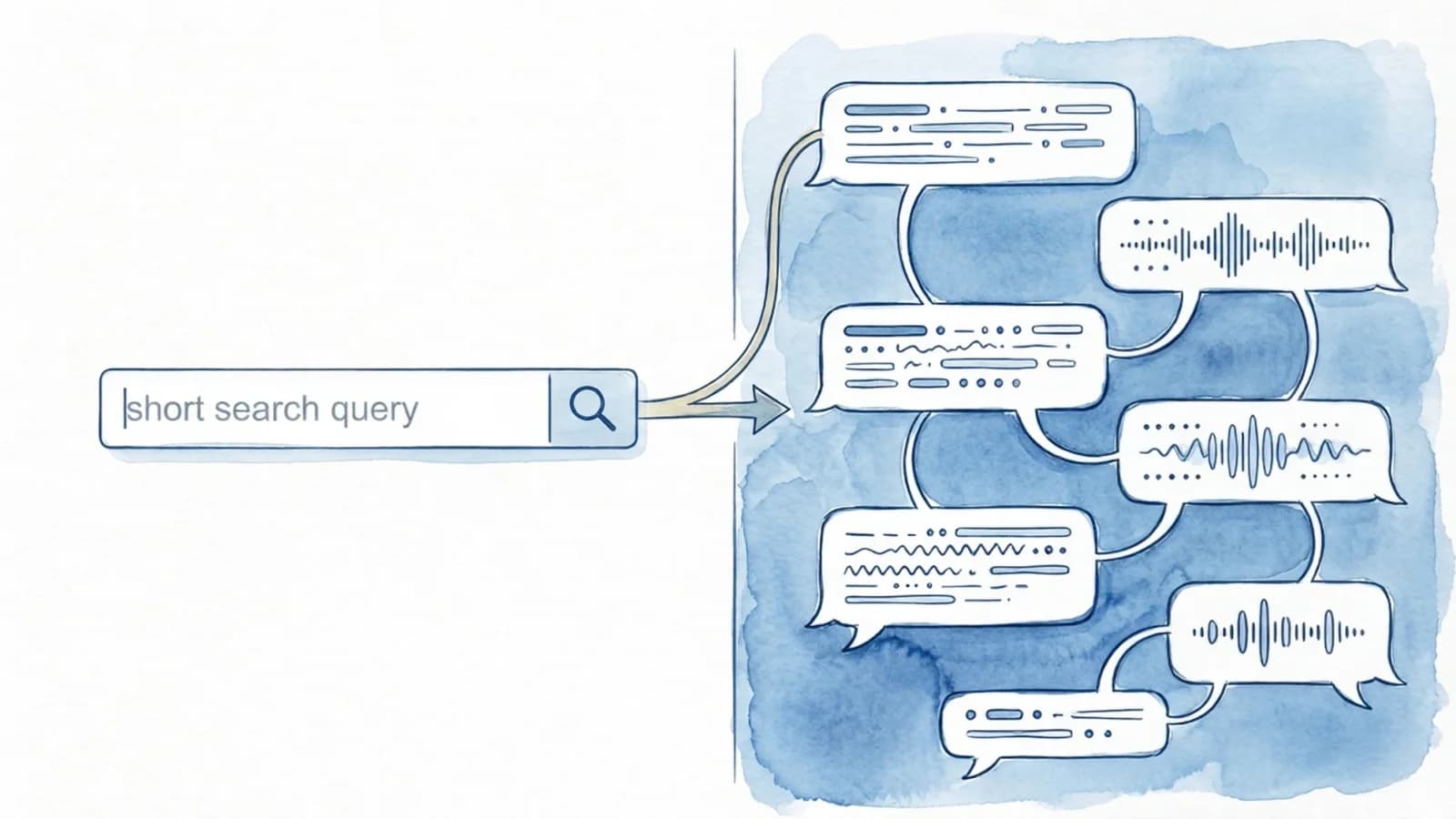
En dan de vorm. Een gemiddelde Google-zoekopdracht bestaat uit 3,4 woorden. Een gemiddelde AI-prompt is rond de 23 woorden lang. En een ChatGPT-gesprek loopt zelden op één vraag uit. In een dataset van bijna 88.000 conversaties is de mediaan zes turns. Bij aankoopgesprekken loopt dat aantal op. Mensen hebben hele conversaties met de tool en geven hun specifieke situatie, gedachten en gewenste output mee: "Ik ben een freelance marketeer met beperkt budget, ik werk vooral aan B2B-content, ik twijfel tussen optie X en Y, wat raad je aan?" Dat soort gesprekken voerde niemand met Google. Het kon technisch wel; het werkte alleen niet.
Een gemiddeld AI-gesprek bevat zes turns. Een gemiddelde Google-zoekopdracht bestaat uit 3,4 woorden.
Drie scenario's, één gesprek per stuk
Wat verandert er nu in concreet zoekgedrag? Drie herkenbare situaties.
De vakantieplanner. Op Google: "vakantie Italië september kindvriendelijk". In ChatGPT: "We willen met twee kinderen van 6 en 9 in september een week weg, niet te warm, met cultuur voor ons en zwembad voor hen, budget rond €3000. Wat raad je aan?" Op Google had je hier minimaal vier zoekopdrachten voor nodig en de uiteindelijke afweging moest je zelf maken. In één prompt combineer je nu brede oriënterende verkenning, toets je het aan jouw voorwaarden en verwacht je een concrete shortlist als output.
De laptopkeuze. Op Google: "beste laptop video editing 2026". In Perplexity: "Ik monteer eens per maand korte video's, geen 4K, gebruik 'm vooral voor schrijven en research, draag 'm dagelijks mee. Vergelijk de drie beste opties onder €1500 op accuduur, gewicht en upgradebaarheid." Hier loopt oriëntatie naadloos over in opties verkennen met scherpe criteria, en dat overgaat in transactie zodra de gebruiker doorklikt.
Het lastige gesprek. Op Google: "hoe geef je feedback aan medewerker". In ChatGPT: "Help me een gesprek voorbereiden met iemand die structureel deadlines mist maar wel goed werk levert. Ik wil eerlijk zijn maar de relatie niet beschadigen." Informatieve, emotionele en generatieve componenten tegelijk. Dit is precies het type interactie dat in Anthropics' onderzoek onder werk en carrière valt, een van de vier dominante guidance-domeinen.
In alle drie de scenario's zie je hetzelfde patroon: één prompt vervangt minimaal vier klassieke zoekopdrachten en bedient meerdere intents tegelijk. Voor SEO betekent dat iets concreets: de zoekvraag waar je content voor optimaliseerde, wordt steeds minder de zoekvraag waar gebruikers daadwerkelijk mee komen.. Het klassieke search intent-model, navigational, informational, commercial en transactional, vangt deze realiteit niet meer (en dat is logisch, want het is een model uit 2002!). We hebben er om die reden een eigen search intent framework voor ontwikkeld dat negen intenties op dertien platformen onderscheidt.
Waarop kun je dan wel sturen?
Als gebruikers zo zoeken en als de prompt zelf 60 woorden lang is en gevuld met persoonlijke context, dan is de logische vervolgvraag voor elke marketeer: waar grijp je in? Op welke laag valt de aanbeveling en wat zien je tools daar eigenlijk van?
Hier loopt de markt nu vast. Er is een groeiend aanbod van prompt-tracking-tools dat met enkele tientallen testprompts probeert te bepalen of je merk wordt genoemd in ChatGPT, Perplexity en Gemini. Die tools verkopen het beeld dat ze je AI-zichtbaarheid meten en kunnen fixen (met AI-gegenereerde tekstuele content). Wat ze in werkelijkheid meten is iets veel beperkters.
Het onzichtbare deel van de zoekopdracht
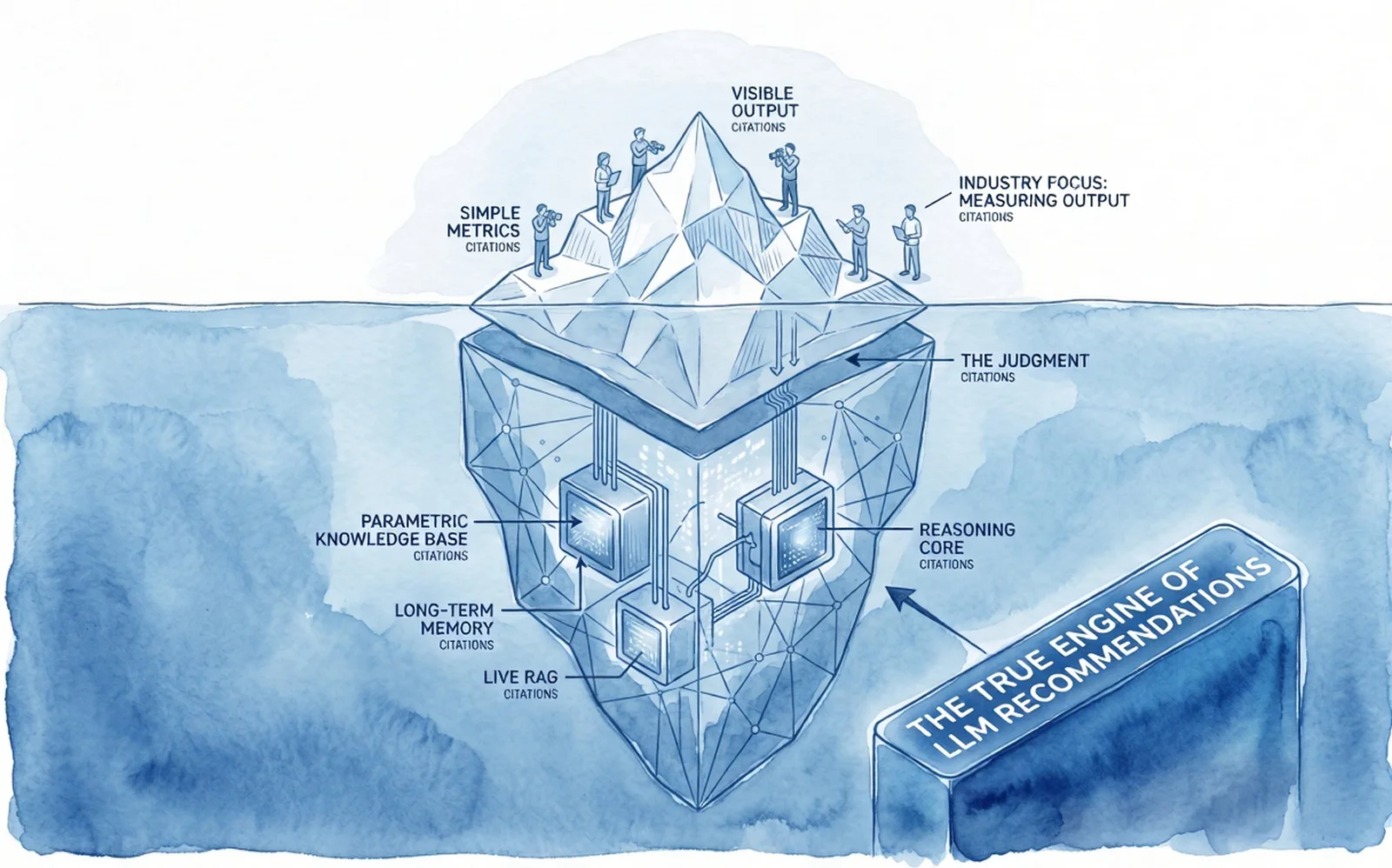
Wat een prompt-tracking-tool ziet, is een synthetisch aftreksel van wat de gebruiker daadwerkelijk doet. In onze deepdive over hoe AI jouw merk wel of juist niet aanbeveelt noemen we dit, in navolging van Grow and Convert, de invisible prompts: de context die het antwoord bepaalt maar nooit in een dashboard terechtkomt. Drie lagen onzichtbare context spelen mee.
Gesprekscontext. Niemand stelt één vraag, krijgt antwoord, en sluit de laptop. Mensen voeren conversaties. Ze lichten hun situatie toe, scherpen criteria aan, vragen door. De aanbeveling die uiteindelijk valt, is gebouwd op alles wat in dat gesprek voorbij is gekomen. Een tracker test altijd in een geïsoleerde, eerste prompt.
Gebruikerscontext. Jouw ChatGPT kent jouw geschiedenis. De mijne niet. Jouw aankoopgedrag, eerdere vragen, voorkeuren en zelfs schrijfstijl spelen mee in wat het model je voorstelt. Een tracker draait altijd in een lege, anonieme sessie zonder die laag.
Formuleringscontext. Iedereen zoekt en formuleert net iets anders. SparkToro liet acht moeders met dezelfde intentie (een basketbalcompetitie voor hun kind vinden) een prompt schrijven. Geen enkele leek op elkaar. De gemiddelde semantische gelijkenis was 0,081, vergelijkbaar met de overlap tussen recepten voor erwtensoep en tiramisu. Test het zelf eens met je collega's: geef een brede zoekopdracht mee, laat iedereen een prompt uitschrijven, en kijk naar de variatie.
Wat hieruit volgt, is geen kleine nuance. Het is een fundamentele beperking van hoe AI-zichtbaarheid op dit moment in de markt gemeten wordt. Je dashboard ziet de output van een geïsoleerde, anonieme testgebruiker en baseert dan zijn hele strategie op. De aanbeveling valt pas na meerdere extra vragen van een echte gebruiker met geschiedenis, context en doorvragen.
invisible prompts: de context bepaalt het antwoord maar zie je niet terug in een dashboard
Zichtbaar zijn ≠ aanbevolen worden
Dat onzichtbare gesprek heeft nog een tweede consequentie die makkelijk wordt gemist: er zit een groot gat tussen geciteerd worden in een AI-antwoord en aanbevolen worden op het moment dat iemand kiest. Je wilt het laatste; trackers meten het eerste.
AIVO Journal documenteerde dit patroon over 195 merken. Hoge visibility-scores in GEO-dashboards gingen vaak samen met zwakke prestaties op het moment dat het commercieel telt: de aanbeveling aan het einde van een meerdelige conversatie. Een ‘koopconversatie’ in ChatGPT of Perplexity is zelden één vraag. Het zijn vier, zes, acht, dertig beurten, van eerste oriëntatie tot concrete keuze. Bij elke beurt past het model criteria-filters toe. Ergens rond beurt 3 of 4 valt komt pas een naam naar voren wat vervolgens weer wordt afgewogen en verder onderzocht.
Onder dat verschil zit iets structureels. AI-systemen putten uit twee soorten bewijs:
De retrieval-laag: het web dat het model live raadpleegt, met citaties, vermeldingen en share of voice. Dit is wat bijna alle GEO-tools meten.
De entiteiten- en associatielaag: de getrainde representatie van je merk in de modelgewichten zelf met gestructureerd bewijs over wie je bent en waar je voor staat. Dit is wat de aanbeveling levert op het moment dat het ertoe doet, en dit is wat bijna geen tool meet.
Dit noemen ze de layer mismatch: het gat tussen waar merken hun visibility-budget aan besteden en waar AI in werkelijkheid uit put als het om aanbevelingen gaat. Als die twee lagen uit elkaar lopen, zie je jouw scores in mooi vormgegeven dashboards stijgen terwijl je sales niet bewegen. Tja, leg dat maar eens uit aan de directie, want die gaf wel het budget voor die nieuwe tool die je absoluut nodig had, en verwacht dan ook commercieel resultaat, niet alleen een stijgend lijntje.
Vijf principes voor wat dan wel werkt
Als de zoekvraag onzichtbaar is en de aanbeveling rond beurt 4 valt op een laag die je tools niet zien, waarop kun je dan wél sturen? Vijf principes die we bij klanten hanteren.
1. Schrijf voor het gesprek, niet voor de prompt
De vraag die je trackt ("beste tool voor X") is niet hoe iemand het stelt. Het is hoe iemand er na vier follow-ups op uitkomt. Je content moet de tussenstappen ondersteunen: vergelijkingen, alternatieven, wanneer wel en wanneer niet jij, scenario-specifieke nuances. Een perfect geoptimaliseerde SEO-pagina die hoog scoort op die korte ouderwetse Google-zoekopdracht, garandeert nog niets over wat het model in beurt 4 doet.
2. Lever het bewijs voor specifieke situaties
AI-tools nemen de brede oriëntatie over. Mensen klikken alleen nog door bij keuzemomenten, om te valideren en de transactie uit te voeren. Daarom ligt de CTR van AI Search structureel lager dan die van klassieke SEO. Dat is een logisch gevolg van hoe antwoordmachines werken, geen probleem dat je oplost door harder te ‘SEO'en’.
Reken AI-zichtbaarheid daarom niet af op verkeer, maar op sales-impact en branded search lift. En lever het model alle munitie om jou aan te bevelen op het juiste moment. Daar wordt content nu zwaarder: "[Jij] vs [concurrent]", "[Jij] voor [specifieke sector]", "Is [jij] geschikt voor [concreet scenario]". Dit is content die het model concrete argumenten geeft om jou in een gerichte situatie te noemen.
3. Bouw aan een herkenbare entiteit, niet alleen aan je website
Een vage merkpositie wordt niet aanbevolen, niet door mensen en niet door modellen. AI bouwt zijn beeld op uit reputatie. Uit alles wat het over je tegenkomt in het hele ecosysteem. Als je site een ander verhaal vertelt dan je cases, en je cases iets anders dan je LinkedIn, dan bouw je geen entiteit. Je bouwt een vage wolk. Wolken kunnen geciteerd worden, maar zelden aanbevolen.
Hier ligt ook de link met die tweede laag. Een herkenbare entiteit met consistente associaties is wat een model meeneemt in zijn uiteindelijke aanbevelingen. Niet wat je vorige week hebt gepubliceerd.
4. Wees waardevol aanwezig waar je doelgroep zich oriënteert
Veel GEO-rapporten werken omgekeerd. Ze analyseren miljoenen citaties, ontdekken dat Reddit, LinkedIn en YouTube vaak voorkomen, en concluderen: "Ga daar aanwezig zijn." Dat is alsof je alle ingrediënten van duizenden supermarktproducten noteert, ontdekt dat water en tarwe het meest voorkomen, en concludeert dat je voor een succesvol product vooral water en tarwe moet gebruiken. Je beschrijft een uitkomst en verkoopt die als recept.
De vraag is niet welke platformen gemiddeld hoog scoren in citatierapporten. De vraag is waar jouw doelgroep zich oriënteert als ze zelf onderzoek doet. Dat zijn vaak vakmedia, podcasts, nichefora en communities die in geen enkel algemeen rapport bovenaan staan. Breng die in kaart,, kijk waar je inhoudelijk kunt bijdragen, en zorg dat de associatie tussen jouw merk en de juiste categorieën, use cases en doelgroepen daar gevestigd wordt.
5. Gebruik prompt-tracking als thermometer, niet als kompas
Trackers meten of je genoemd wordt. Ze vertellen je niet waarom. Ze zijn nuttig om over tijd te zien of je zichtbaarheid groeit, om te spotten welke bronnen AI gebruikt als het je wel aanbeveelt, en om nieuwe concurrenten in beeld te krijgen. Ze zijn een feedbacklaag op je strategie. Als je ze daarvoor inzet, doen ze hun werk. Als je ze als strategie inzet, optimaliseer je voor zichtbaarheid en zoveel mogelijk citaties, niet om vaker aanbevolen te worden.
Een diepere uitwerking van de vijf lagen waarop merken in AI worden aanbevolen lees je in Waarom ChatGPT je concurrent aanbeveelt en jou niet.
Maak het niet moeilijker dan het is
GEO en AI Search worden in de markt vaak verkocht als een totaal nieuwe specialisatie met eigen tools, eigen dashboards en eigen jargon. Dat is commercieel handig. Er kan een team aan worden toegewezen, een budget aan worden gehangen, een KPI aan worden geknoopt. Voor wie iets te verkopen heeft, zijn complexiteit en noviteit een verdienmodel. Andersom gebeurt het ook: bestaande SEO-partijen roepen vooral keihard dat GEO eigenlijk gewoon SEO is, hooguit met wat kleine aanpassingen, en dat zij dus als beste weten hoe je dat doet.
De merken die nu structureel worden aanbevolen door AI doen geen geheime dingen. Ze waren bij wijze van spreken vijftien jaar geleden al begonnen met het optimaliseren voor AI. Hun positionering is kraakhelder. Ze leveren intern het bewijs voor wie ze zijn en voor wie ze de beste keuze zijn. Ze zijn waardevol aanwezig op plekken waar hun doelgroep zich oriënteert. En anderen, onafhankelijk van hen, bevestigen dat verhaal.
Dat is het. Geen trucjes. Geen geheim framework. Het werk om in dat onzichtbare gesprek aanbevolen te worden, gebeurt grotendeels buiten het dashboard om.