TL;DR
OpenAI and Anthropic have shown, using their own data, that people search differently now: longer prompts, multiple intents, conversations instead of queries. Most GEO tools don't measure that. They test isolated prompts in empty sessions, while the actual recommendation falls inside a conversation full of personal context that no dashboard ever sees. What does work: clear positioning, internal evidence for specific situations, a recognizable entity across the entire ecosystem, and independent confirmation of your story. No secret framework. The real work happens outside the dashboard.
The familiar moment
You type something into ChatGPT or Claude and realize halfway through that you would never have asked Google this two years ago. "I have a difficult conversation with a client next week. The project has gradually become much bigger than we agreed on, but the budget has stayed the same. I want to be honest without damaging the relationship. Help me build it." No short query. No list of blue links. And certainly no intent to visit a website that would partially answer the question.
For SEO marketers, this moment is uncomfortable for two reasons. First, it lands: we're using AI for questions Google never had a good answer to. Second, most GEO approaches on the market today ignore this reality. They measure visibility through isolated test prompts and present that as a strategy, while the actual decision falls inside a conversation your dashboard will never see.
This article examines what recent research reveals about how people use LLMs, what that means for how brands are recommended, and where we believe the real work lies.
What OpenAI and Anthropic show themselves
What's interesting about the data we're about to discuss isn't only what the numbers say. It's who published them. OpenAI and Anthropic researched this behavior and released their findings. The parties that can see exactly how people use their models apparently consider the shift significant enough to dedicate public research to it. For marketers, that's a signal in itself.
OpenAI published a major study on ChatGPT usage in September 2025, based on an anonymized sample of over a million consumer conversations. The three primary roles they identified summarize the picture well:
49% Asking — advice, explanation, interpretation
40% Doing — writing, planning, coding, structuring
11% Expressing — reflection, brainstorming, personal expression
That "Doing" half doesn't fit any classic SEO framework. No information is being sought there. Something is being made: an email, an outline, a piece of code, a shortlist. For traditional search engines, that half of the market is simply invisible, because no SERP was ever generated.

Anthropic published its own analysis in late April 2026, based on a sample of 1,000,000 Claude conversations (around 639,000 unique users). They found that roughly 6% of all conversations consist of personal guidance: questions like "Should I take this job?", "How do I talk to my neighbor?", "Should I move abroad?". Three quarters of those guidance conversations fell into four domains: health and well-being (27%), work and career (26%), relationships (12%), and personal finance (11%). People aren't looking for information here. They're looking for a second opinion.
Then there's the form. The average AI prompt is around 60 words long. The average Google search is 3.4 words. People bring their specific situation, thoughts, and desired output: "I'm a freelance marketer with a limited budget, I work mostly on B2B content, I'm torn between option X and Y, what would you recommend?" No one wrote prompts like that on Google. Not because they couldn't, but because it didn't work anyway.
Research by Semrush among over a thousand US consumers (December 2025) confirms that this behavior translates into the commercial journey. 77% use AI and search engines side by side in the same purchase process. 53% compare products through AI. 43% discovered a brand they didn't know yet that way. AI functions as a filter and orientation layer in that study, rarely as the closer of the transaction. It's US data, so some restraint is warranted, but the direction matches what we see at clients in the European market.
Three scenarios, one conversation each
What's actually changing in concrete search behavior? Three recognizable situations.
The vacation planner. On Google: "family vacation Italy September". In ChatGPT: "We want to go away with two kids aged 6 and 9 for a week in September, not too hot, with culture for us and a pool for them, budget around €3,000. What do you recommend?" On Google, you'd need at least four queries to get there, and you'd still have to make the final call yourself. In one prompt, you now combine broad exploration, comparison against your constraints, and a concrete shortlist as output.
The laptop choice. On Google: "best laptop video editing 2026". In Perplexity: "I edit short videos once a month, no 4K, mainly use it for writing and research, carry it daily. Compare the three best options under €1,500 on battery life, weight, and upgradability." Here, orientation flows directly into option-evaluation against sharp criteria, then transitions into transaction the moment the user clicks through.
The difficult conversation. On Google: "how to give feedback to an employee". In ChatGPT: "Help me prepare a conversation with someone who consistently misses deadlines but does good work. I want to be honest without damaging the relationship." Informational, emotional, and generative components at once. This is exactly the type of interaction that falls under work and career in Anthropic's research, one of the four dominant guidance domains.
In all three scenarios, you see the same pattern: one prompt replaces at least four classic queries and serves multiple intents at once. For SEO, that means something concrete. The query you optimized your content for is increasingly less the query users actually arrive with.
The pivot: so what can you steer on?
If users search like this, and if the prompt itself is 60 words long and packed with personal context, the logical follow-up question for any marketer becomes: where do you intervene? On which layer does the recommendation fall, and what do your tools actually see of that?
This is where the market is getting stuck. There's a growing supply of prompt-tracking tools that aim to determine, using a few dozen test prompts, whether your brand is mentioned in ChatGPT, Perplexity, and Gemini. These tools sell the idea that they measure your AI visibility. What they actually measure is something far more limited.
The invisible part of the search
What a prompt-tracking tool sees is a synthetic abstraction of what the user actually does. In our deep dive on how AI does and doesn't recommend your brand we call this, following Grow and Convert, the invisible prompts: the context that determines the answer but never makes it to a dashboard. Three layers of invisible context play a role.
Conversational context. No one asks one question, gets an answer, and closes the laptop. People have conversations. They explain their situation, sharpen criteria, ask follow-ups. The recommendation that eventually falls is built on everything that came before it. A tracker always tests in an isolated, first prompt.
User context. Your ChatGPT knows your history. Mine doesn't. Your purchase history, earlier questions, preferences, even your writing style all factor into what the model proposes. A tracker always runs in an empty, anonymous session without that layer.
Phrasing context. Everyone searches for and phrases things slightly differently. SparkToro had eight mothers with the same intent (find a basketball league for their child) write a prompt. None of them looked alike. The average semantic similarity was 0.081, comparable to the overlap between recipes for pea soup and tiramisu. Try it yourself: give your colleagues a broad search task, have everyone write out their prompt, and look at the variation.
What follows from this isn't a small nuance. It's a fundamental limitation in how AI visibility is currently measured in the market. Your dashboard sees turn 1 of an isolated, anonymous test user. The recommendation falls at turn 4 of a real user with history, context, and follow-up questions.
Visible ≠ recommended
That invisible conversation has a second consequence that's easy to miss. There's a large gap between being cited in an AI answer and being recommended when someone chooses.
AIVO Journal documented this pattern across 195 brands. High visibility scores in GEO dashboards often went hand in hand with weak performance at the moment that matters commercially: the recommendation at the end of a multi-turn conversation. A purchase conversation in ChatGPT or Perplexity is rarely a single question. It's four, six, eight turns, from initial orientation to concrete choice. The model applies the criteria filters at each turn. The name usually drops somewhere around turn 3 or 4.
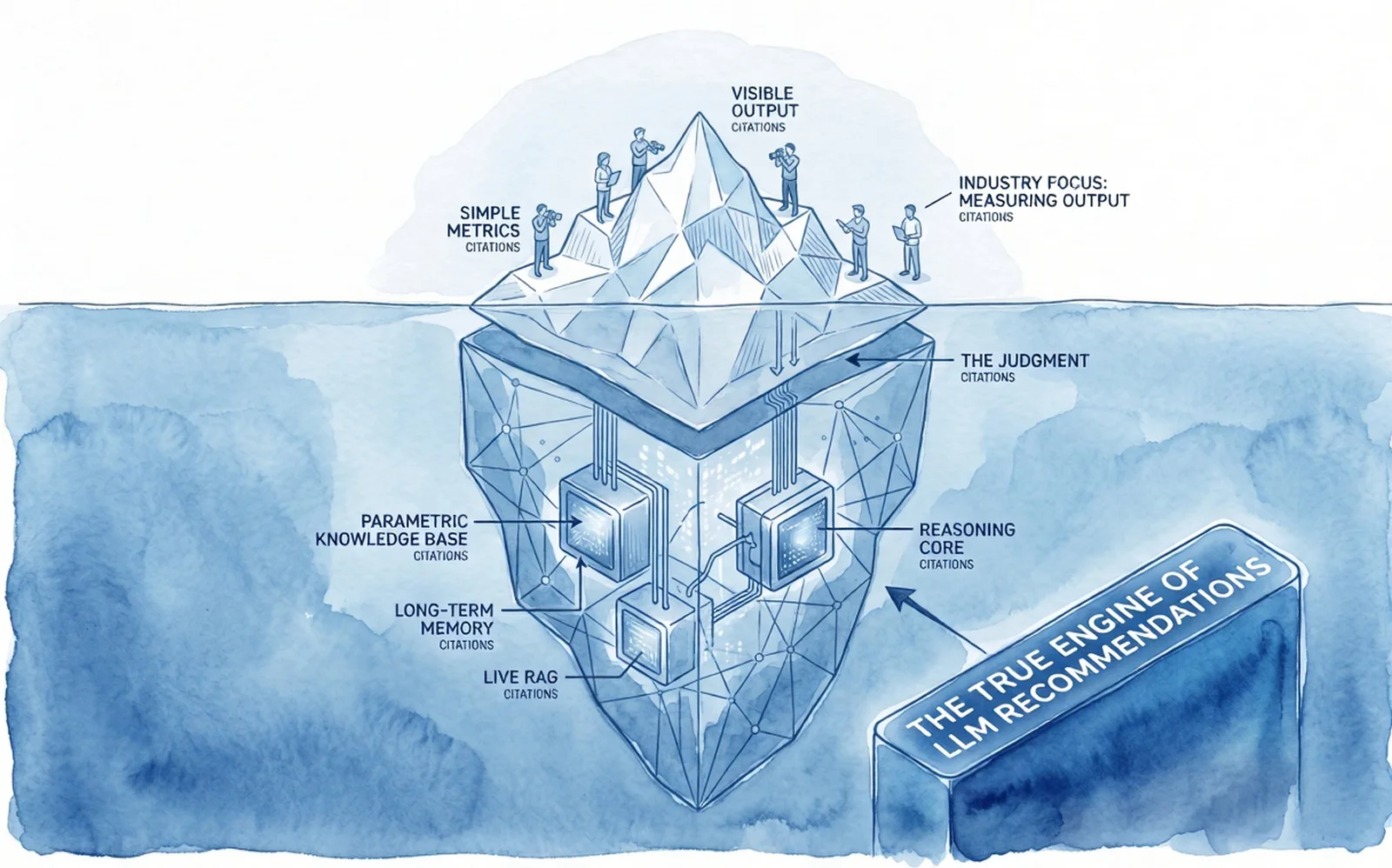
There's something structural underneath that gap. AI systems draw on two kinds of evidence:
The retrieval layer: the web the model consults live, with citations, mentions, and share of voice. This is what almost all GEO tools measure.
The entity and association layer: the trained representation of your brand in the model weights themselves, plus Wikidata, Wikipedia, and structured evidence about who you are and what you stand for. This is what produces the recommendation that counts at the moment, and it's what almost no tool measures.
This is called the layer mismatch: the gap between where brands spend their visibility budget and where AI actually draws from when it comes to recommendations. When those two layers diverge, you see your dashboards rise while your sales don't move.
Five principles for what does work
If the search query is invisible and the recommendation falls around turn 4 on a layer your tools can't see, what can you actually steer on? Five principles we apply with clients.
1. Write for the conversation, not the prompt
The query you track ("best tool for X") isn't how someone phrases it. It's where someone arrives after four follow-ups. Your content needs to support the intermediate steps: comparisons, alternatives, when you and when not, scenario-specific nuances. A perfectly optimized SEO page that scores high on that short, old-fashioned Google query guarantees nothing about what the model does at turn 4.
2. Provide the evidence for specific situations
AI tools take over the broad orientation. People only click through at decision moments now, to validate and execute the transaction. That's why the CTR of AI Search is structurally lower than classic SEO. That's a logical consequence of how answer machines work, not a problem you solve by doing more SEO.
Don't measure AI visibility on traffic, then. Measure it on sales impact and branded search lift. And give the model all the ammunition to recommend you at the right moment. That's where content needs to get heavier now: "[You] vs [competitor]", "[You] for [specific sector]", "Is [you] suitable for [concrete scenario]". This is content that gives the model concrete arguments to mention you in a targeted situation.
3. Build a recognizable entity, not just a website
A vague brand position doesn't get recommended, not by humans and not by models. AI builds its picture from reputation. From everything it encounters about you across the ecosystem. If your site tells one story, your case studies another, and your LinkedIn yet another, you're not building an entity. You're building a fuzzy cloud. Clouds can be cited, but rarely recommended.
This also connects to that second layer. A recognizable entity with consistent associations is what a model carries into turn 4. Not what you published last week.
4. Be valuably present where your audience orients itself
Many GEO reports work backward. They analyze millions of citations, discover that Reddit, LinkedIn, and YouTube come up most often, and conclude: "Go be present there." That's like cataloguing the ingredients of thousands of supermarket products, discovering that water and wheat appear most frequently, and concluding that a successful product mostly needs water and wheat. You're describing an outcome and selling it as a recipe.
The question isn't which platforms score high in citation reports on average. The question is where your audience orients itself when they go looking on their own. Those are often trade publications, podcasts, niche forums, and communities that don't appear at the top of any general report. Map them, see where you can contribute meaningfully, and make sure the association between your brand and the right categories, use cases, and audiences gets established there.
5. Use prompt tracking as a thermometer, not a compass
Trackers measure whether you're mentioned. They don't tell you why. They're useful for seeing whether your visibility grows over time, for spotting which sources AI uses when it does recommend you, and for catching new competitors in view. They're a feedback layer on your strategy. Used that way, they do their job. Used as strategy, you optimize for turn 1 in a world where the choice falls at turn 4.
A deeper exploration of the five layers on which brands get recommended in AI is in Why ChatGPT recommends your competitor and not you.
Don't make it harder than it is
GEO and AI Search are often sold in the market as a totally new specialism with their own tools, dashboards, and jargon. That's commercially convenient. A team can be assigned, a budget attached, a KPI hung on it. For anyone with something to sell, complexity and novelty are a business model. The reverse happens too: existing SEO firms loudly insist that GEO is really just SEO, and that they therefore know best how to do it.
The brands that are now structurally being recommended by AI aren't doing anything secret. They were, figuratively speaking, optimizing for AI fifteen years ago. Their positioning is crystal clear. They internally provide the evidence for who they are and who they're the best choice for. They're valuably present where their audience orients itself. And others, independent of them, confirm that story.
That's it. No tricks. No secret framework. The work to be recommended in that invisible conversation happens largely outside the dashboard.